.jpg)
삼성전자가 세계 최대 AI 반도체 기업 엔비디아(NVIDIA)의 GPU를 5만개 이상 도입해 AI 팩토리 인프라를 확충하고, 엔비디아에 대한 HBM4 공급도 거의 확실한 단계에 이르며, AI 생태계에서 양사 협업을 강화한다.
2025-11-03 10:33:46by 배종인 기자

SK그룹이 엔비디아(NVIDIA)와 손잡고 국내 제조업 생태계의 디지털 전환을 이끌 ‘제조 AI 클라우드’를 구축한다. 이는 아시아 최초로 엔비디아의 옴니버스(Omniverse) 플랫폼을 활용한 제조 AI 클라우드 상용화 사례로, 국내 스타트업과 공공기관에도 개방해 제조 AI 생태계 육성에 나선다.
2025-11-03 12:12:34by 명세환 기자

APEC 및 엔비디아 지포스 한국 출시 25주년을 맞아 한국을 방문한 엔비디아(NVIDIA)의 젠슨 황(Jensen Huang) CEO가 한국에 AI 데이터 센터를 위한 GPU 공급을 약속하며, 우리나라가 첨단 AI 데이터 센터 구축에 필요한 핵심 부품을 확보했지만, 막대한 도입 비용을 넘어서는 효과를 거두기 위해서는 AI 데이터 센터 계획부터 구축, 활용까지 철저한 계획이 뒷받침돼야 한다는 의견이 제시되고 있다.
2025-11-04 14:03:12by 명세환 기자

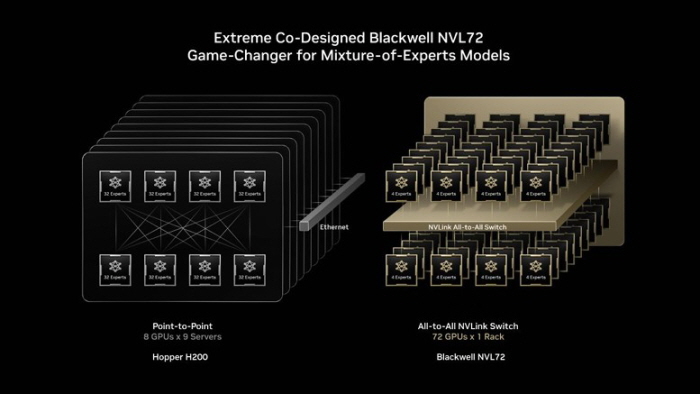
슈퍼마이크로컴퓨터(Super Micro Computer, Inc., 이하 슈퍼마이크로)가 엔비디아 베라 루빈 NVL144 및 NVL144 CPX 아키텍처를 기반 차세대 AI 인프라 솔루션을 발표하며 미국 연방 정부의 보안·성능·규제 요건을 충족했다.
2025-11-04 16:58:32by 배종인 기자

기존의 AI가 디지털 데이터 속에서 추론과 생성에 집중했다면 피지컬 AI(Physical AI)는 센서, 엣지 컴퓨팅, 로봇, 제어 시스템 등을 통해 현실 세계에서 직접 행동하고 반응한다. 피지컬 AI의 구현은 현실 세계에서 AI가 직접 행동하고 문제를 해결하기 때문에 산업 혁신과 자동화를 크게 진화 시킬 수 있으며, 현실 세계와 직접 상호작용한다. 이에 따라 엔비디아, 테슬라, 구글을 비롯해 글로벌 기업들은 피지컬 AI에 막대한 투자를 진행 중이며, 관련 시장도 폭발적으로 증가할 전망이다. 이러한 피지컬 AI를 구현하기 위해서는 센서 등 인식 기술을 비롯해서 실시간 데이터 처리를 위한 로컬 연산 등 엣지 컴퓨팅 및 임베디드 시스템, 로보틱스 및 제어기술이 필수다. 이에 e4ds news는 연재 기획을 통해 피지컬 AI의 개념에서부터 시장 전망, 관련 기술, 실제 사례 등 핵심 기술과 구현 전략을 살펴보는 자리를 마련했다. 이번 편은 피지컬 AI의 감각 기관인 센서에 대해 다룬다.
2025-11-11 08:48:24by 명세환 기자

AI 경량화 및 최적화 기술 전문 기업 노타(대표 채명수)가 글로벌 AI 산업의 핵심 벤치마크로 평가받는 ‘2025 MAD Landscape’에서 엣지 AI 부문에 2년 연속 이름을 올렸다. 노타는 이번 MAD Landscape에서 엔비디아, 퀄컴, 삼성, 인텔, 애플, AMD 등 글로벌 대기업들과 함께 엣지 AI 부문에 등재되며 기술 경쟁력을 입증했다.
2025-11-13 16:21:03by 명세환 기자

피지컬 AI 확산의 핵심 열쇠로 꼽히는 통합운영체계(Integrated Operating System) 선점하기 위해 엔비디아를 필두로 우리나라를 비롯한 주요 국가들이 개발과 표준화에 적극 나서고 있다.
2025-12-01 16:08:35by 명세환 기자
