


인공지능 기술과 소프트웨어로 기능하는 자동차 등 디바이스에서 요구하는 데이터양이 막대해지고 있다. 늘어나는 데이터 양에 대응하고 이러한 데이터를 활용할 수 있는 기술을 갖추는 데 시장 니즈가 높아지고 있는 가운데 단순히 데이터 처리 속도를 만족하면서 처리할 수 있는 데이터 양까지 충족하기 위해선 프로세서를 지원하는 메모리 속도가 필수적으로 뒷받침돼야 한다.
2023-06-12 12:25:04by 명세환 기자
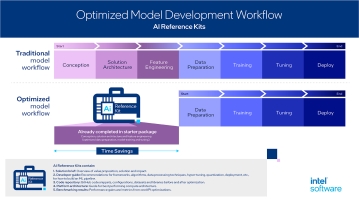
산업 솔루션이 시장에 배포되는 시간을 단축시키는 AI 참조 키트가 오픈소스 형태로 인텔의 개발자 커뮤니티에 지속 업데이트되며 그 개수를 늘려나가고 있다.
2023-07-25 15:14:23by 명세환 기자
.jpg)
일반적으로 AI 성능을 평가하는 가장 신뢰할 만한 지표인 MLPerf는 공정하고 반복 가능한 성능 비교를 가능하게 한다. MLPerf에서의 높은 지표가 AI 반도체 경쟁력으로 작용하고 있는 가운데 인텔이 ML커먼스 벤치마크에서 경쟁 제품 대비 비교 우위의 결과를 달성했다는 소식이 전해졌다.
2023-09-12 16:32:39by 명세환 기자

인텔의 연례 개발자 행사인 인텔 이노베이션 2023(Intel Innovation 2023) 둘째 날을 맞아 그렉 라벤더(Greg Lavender) 인텔 최고기술책임자(CTO)가 인텔의 개발자 중심, 개방형 생태계 철학이 어떻게 인공지능이 제공하는 기회를 모두가 접하도록 돕는지에 대해 상세하게 소개했다.
2023-09-21 15:15:27by 배종인 기자

인텔이 인텔ⓡ 코어™ i9-14900K를 필두로 한 인텔 코어 14세대 데스크톱 프로세서 제품군을 출시하며, 세계에서 가장 빠른 데스크톱 클럭 속도를 통해 최고 성능의 데스크톱 및 뛰어난 오버클럭 경험 제공에 나선다.
2023-10-17 11:43:44by 배종인 기자
